

A raíz de la skill de "El informativo de Ángel Martín" he tenido varias preguntas relacionadas con la creación de una skill que simplemente reproduzca una URL con audio. Pensando en eso, sin entrar en complejidad de fechas que tiene la skill del informativo, se me ha ocurrido crear un código base, a modo de plantilla, para tener una skill muy simple que reproduzca audio a partir de una URL pública, hosteando el back en AWS Lambda.
En este post voy a contar cómo crear esa skill paso a paso (sin entrar en el código o en el proceso de distribución ni certificación). Si hay muchos conceptos que desconoces puedes ver mis primeros posts, que cuentan gran parte de la teoría. El código está liberado y con licencia GPL-3.0. Hay pasos que son pura configuración y burocracia de trabajar con AWS pero no son complicados.
El proceso en este caso se podría hacer también con Alexa-Hosted y Node.js. Haré otro post para eso pero por ahora quería aprovechar lo que ya tenía en Kotlin. He creado también un video sobre el proceso, por tanto, si te da pereza leer, puedes ver la película ;)
Casos de uso
Con una skill de este tipo, con el código base, se puede crear una skill que reproduzca un audio al que se debe acceder a partir de una URL pública, HTTPs y en formato MP3 (hay más formatos soportados documentados aquí pero este parece la opción más segura).
Se podría crear una radio, por ejemplo, si tenemos una URL que haga streaming continuo o podemos ir cambiando la URL del audio "en caliente", sin desplegar código, porque lo he creado usando variables de entorno en AWS Lambda. Además le he metido la opción de tener otra variable de entorno para un audio de "fallback" por si falla el audio principal por algún motivo.
No tiene opciones para personalizar respuestas de Alexa porque en principio el caso de uso está orientado a reproducir el audio con simplemente arrancar la skill y, aunque tiene un intent por ser obligatorio, invocarlo de forma one-shot tendrá el mismo resultado que arrancar la skill con un launch request.
Una vez esté sonando el audio vamos a poder pararlo y continuarlo con "Alexa, para" y "Alexa, continúa" respectivamente.
Creando la skill en la Alexa Developer Console
Lo primero que tenemos que hacer es crear una skill y para ello podemos hacer uso de la Alexa Developer Console. Ya tengo otros posts donde cuentan los pasos iniciales por lo que no me voy a repetir aquí pero, como resumen:
- Crearse una cuenta de desarrollador de Amazon Alexa
- Crear una skill desde la Alexa Developer Console que sea de tipo Custom y provisionaremos el back por nuestra cuenta
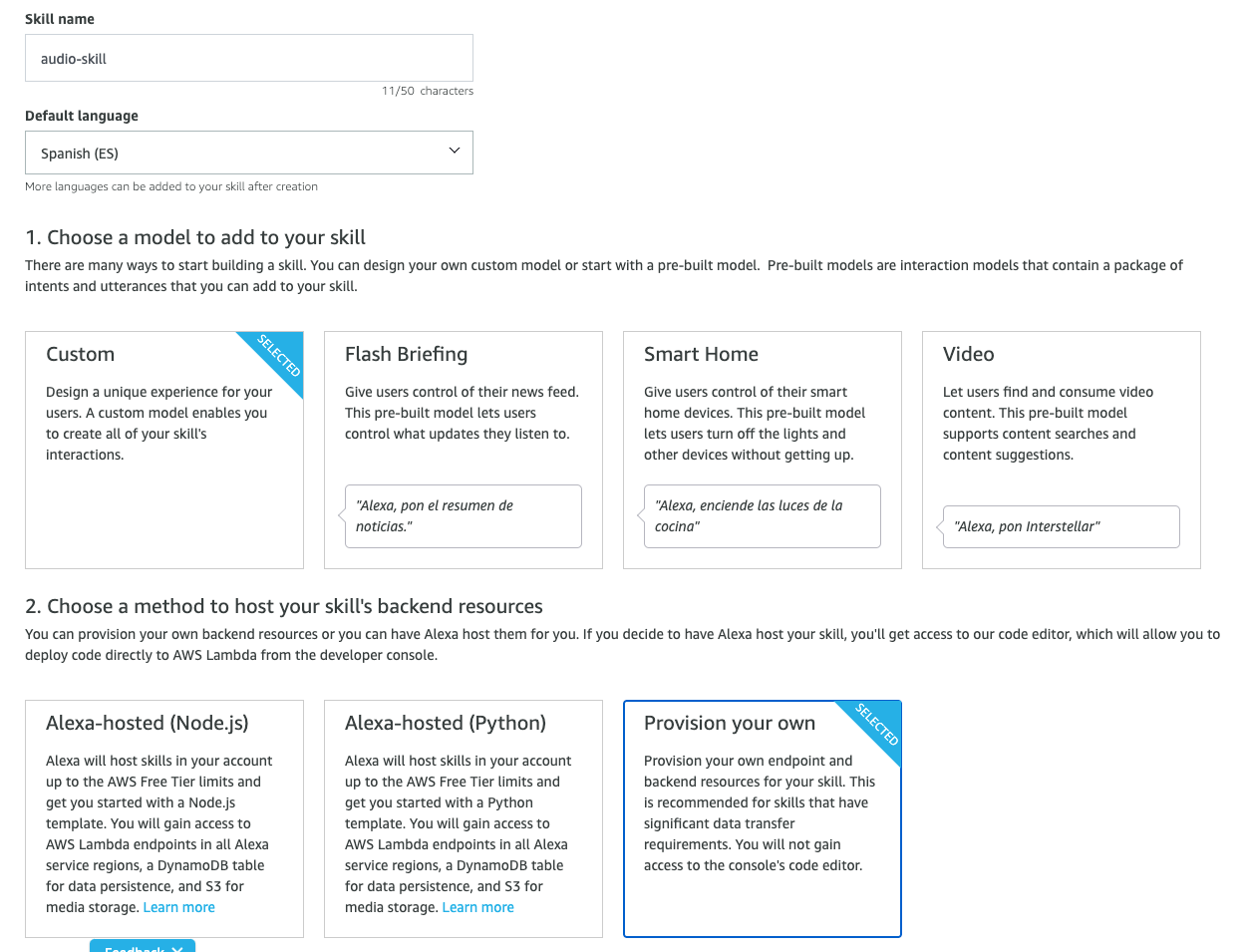
- Elegimos la plantilla básica para el modelo de interacción. Luego vamos a sustituir lo que se cree entonces no será problema.

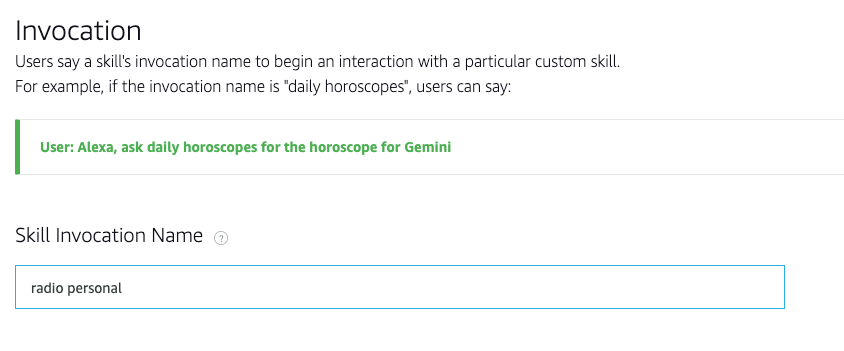
- Elegimos el invocation name
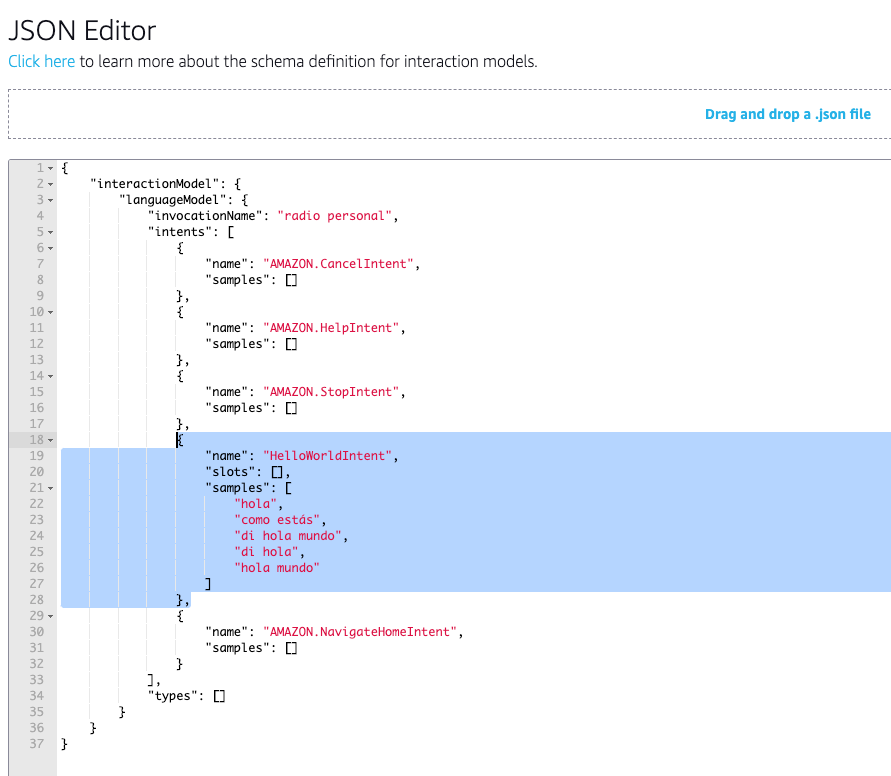
- El modelo de interacción creado ya tiene un Intent custom que se llama HelloWorldIntent. Vamos a sustituir ese Intent por uno propio. Es cierto que para usar esta skill no vamos a necesitar un intent pero es obligatorio tener uno propio. En el editor JSON sustituimos el código de ese intent por:
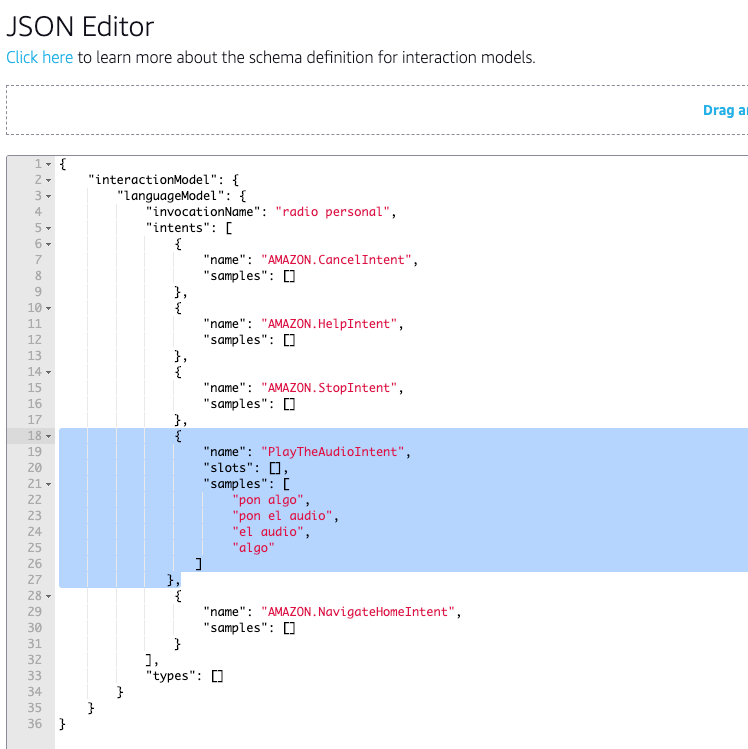
- Al ser una skill de Audio tenemos que activar la interface de Audio Player o nuestra skill fallará al intentar reproducirse en un dispositivo.
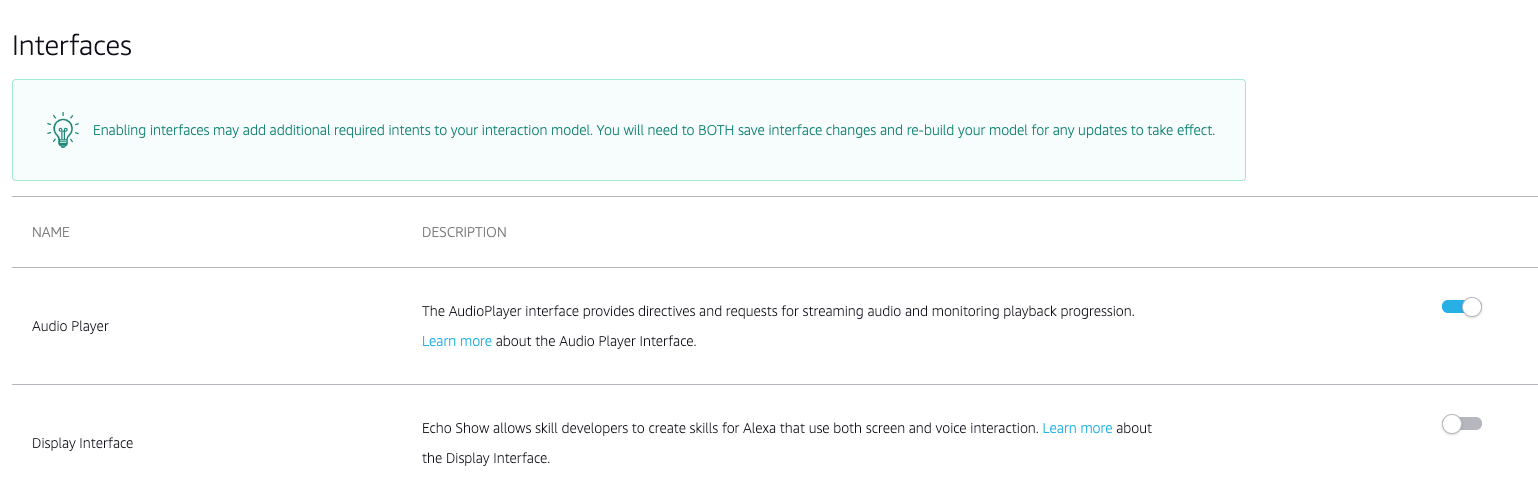
Llegados a este punto deberíais poder construir el modelo de forma exitosa. Nos faltaría el paso de declarar el endpoint correcto pero eso lo haremos después de configurar la función lambda.
Creando la función AWS Lambda
Al igual que antes ya había explicado en posts anteriores cómo crear una función lambda para usarla como endpoint de nuestra skill. Voy a resumir los pasos:
- Nos tenemos que crear una cuenta de desarrollador de Amazon para los servicios AWS. Así tendremos acceso al servicio de AWS Lambda (entre otros).
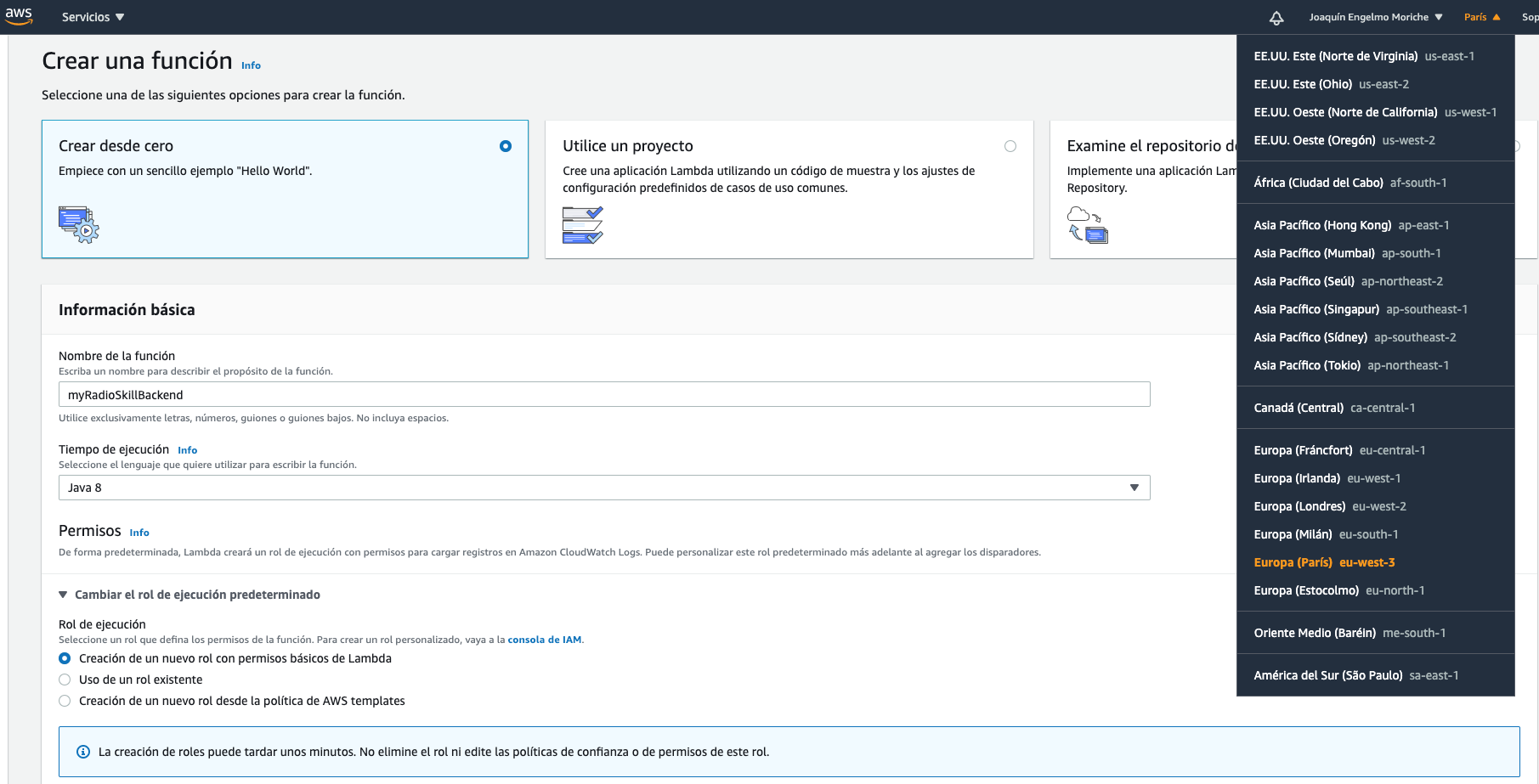
- Creamos una función (ojo con la región, para España la mejor opción actual es la de París). El código de mi proyecto está en Kotlin con lo que seleccionaremos el lenguaje Java 8 (es donde lo tengo ya probado). Vamos a crear también un rol nuevo a no ser que ya tengas uno de antes con permisos correctos para el lambda, los logs de CloudWatch y escritura/lectura en DynamoDB.
Configurando los servicios para usar DynamoDB
Este tipo de skills necesita de persistencia para manejar la acción de "retomar el audio" (pausa/continúa) desde donde lo dejaste si lo paras en algún momento. Para eso haremos uso de DynamoDB.
Por tanto hay dos cosas que debemos hacer:
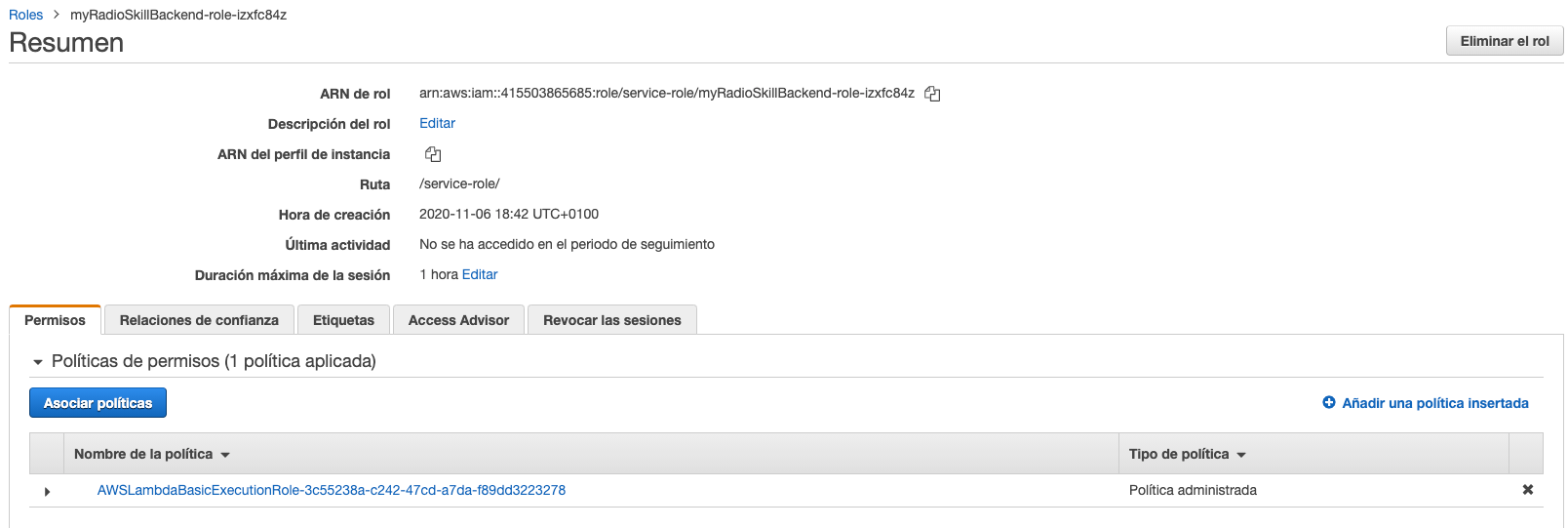
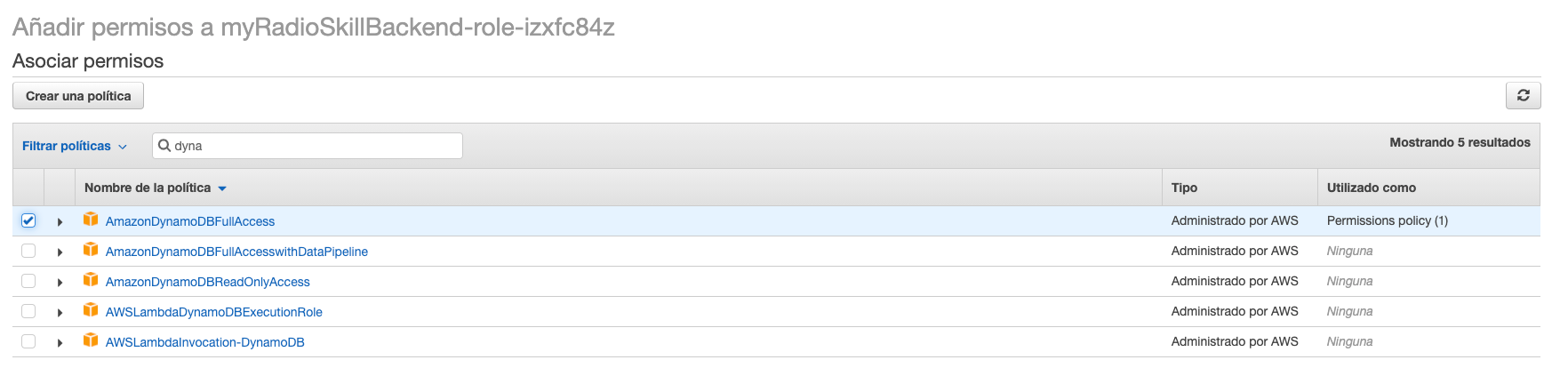
- Añadir los permisos de lectura y escritura en DynamoDB al rol que se creó al crear la función lambda. Para eso desde la pestaña de "Permisos" accedemos a los detalles del rol y le asociamos la política correspondiente.

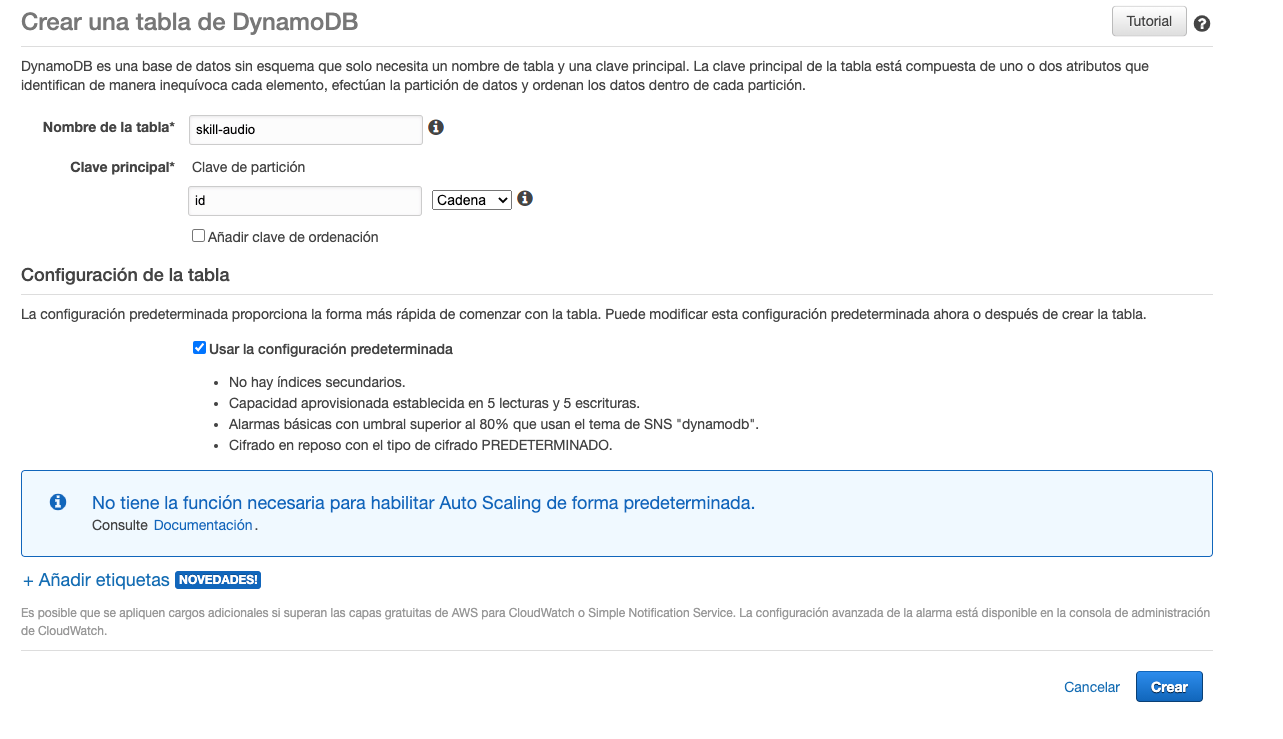
- Crear la tabla previamente o la primera ejecución de la skill fallará porque no estará la tabla creada. Nos vamos al servicio de DynamoDB y creamos una tabla con el nombre que ya está configurado en el código de la lambda
skill-audio.
Desplegando el código de la función lambda
Llegados a este punto tenemos que generar un paquete para desplegarlo en la función lambda. Aquí hay dos opciones:
- Se puede construir en local a partir del código en el repositorio ejecutando la task de Gradle de
shadowJar. Esto generará un fichero.jaren el directoriobuild/libscon el nombrealexa-skill-audio-1.0-all.jar. - Coger el paquete ya generado y que he metido en la raíz del repositorio con el nombre de
alexa-skill-audio-1.0-all.jar.
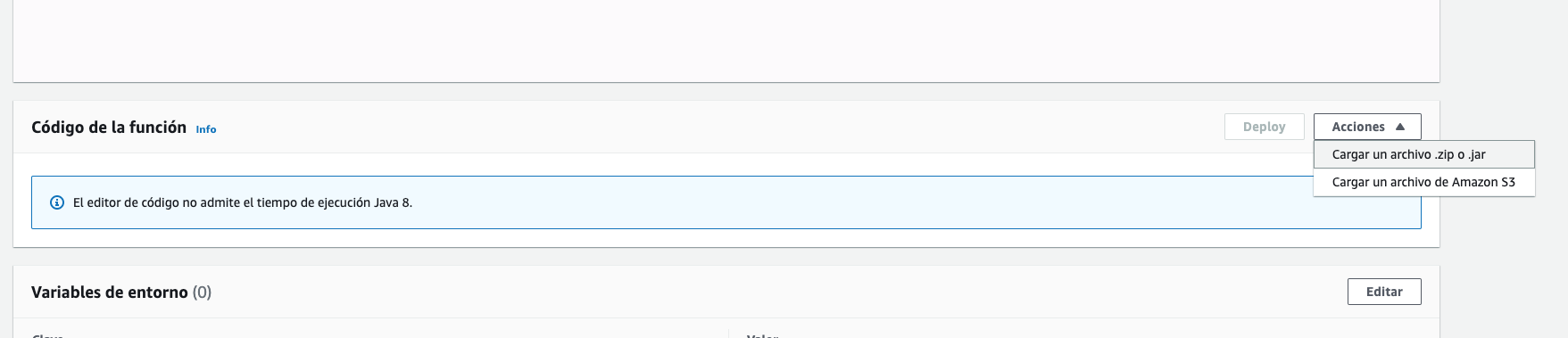
Una vez tenemos el paquete hay que desplegarlo en la función lambda. Aquí lo vamos a hacer a mano pero hay formas de integrar en Gradle esto.
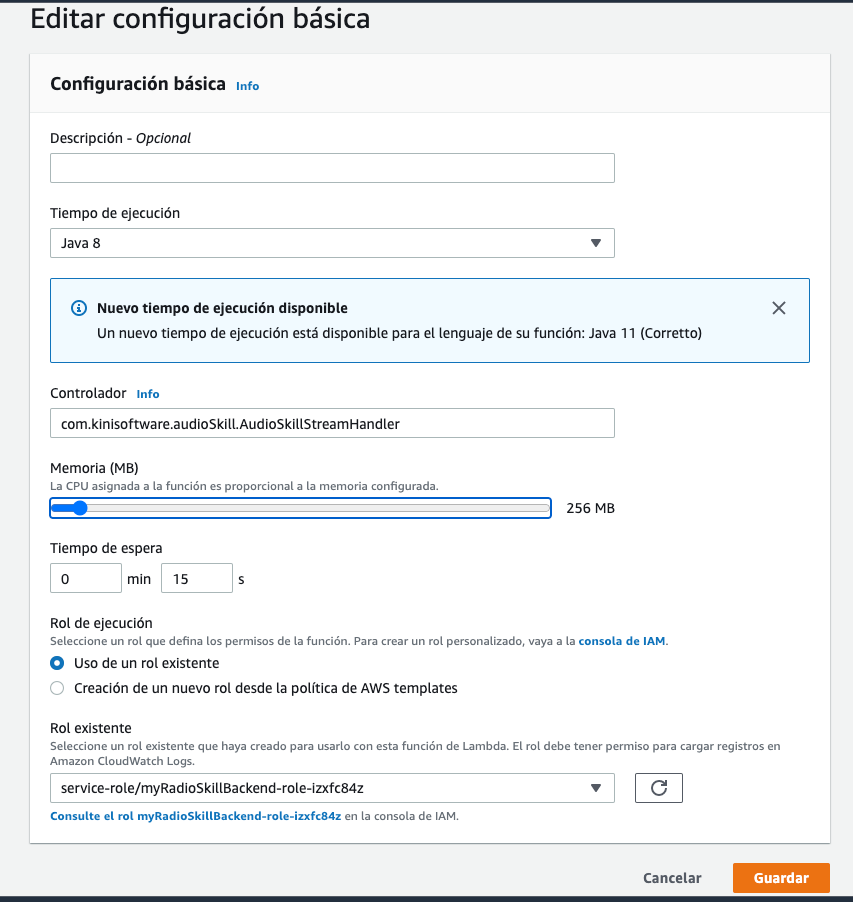
Ahora pasamos a la configuración básica de la lambda (controlador, memoria, etc):
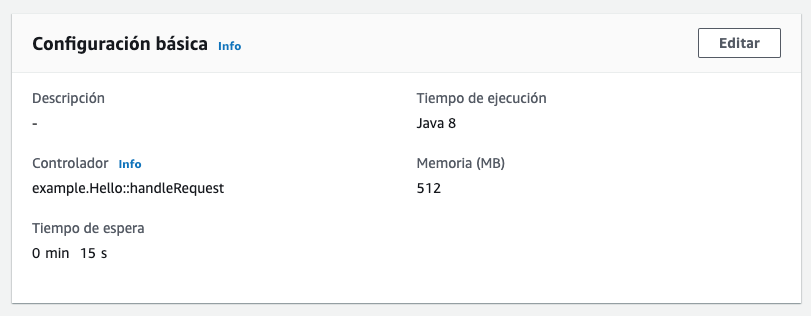
- Hay que poner la ruta del controlado tal como está en el código fuente. Habría que cambiarla a:
com.kinisoftware.audioSkill.AudioSkillStreamHandler - La memoria se puede bajar a 256 (incluso sobre 200) pero creo que cada ejecución usaba 160 o así (eso se puede ver en los logs).
Enganchando la skill
Ahora ya podemos pasar a enganchar la skill con nuestra función lambda. En la Alexa Developer Console habíamos dejado sin modificar la parte del endpoint. Eso es lo que vamos a preparar.
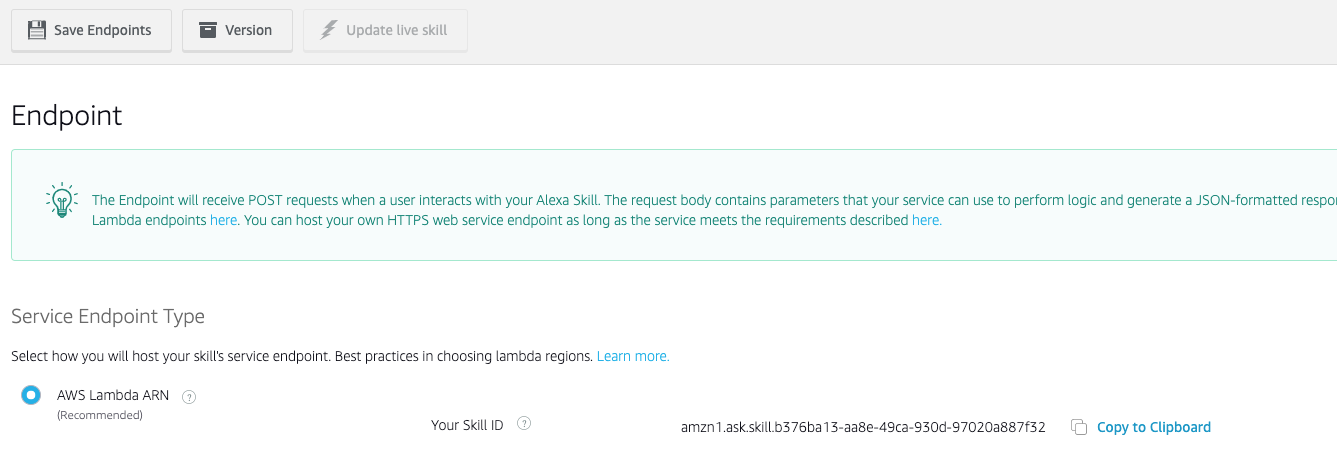
- Copiamos el skill id desde la Alexa Developer Console > Endpoint. Ese id lo vamos a meter en la parte de la lambda.
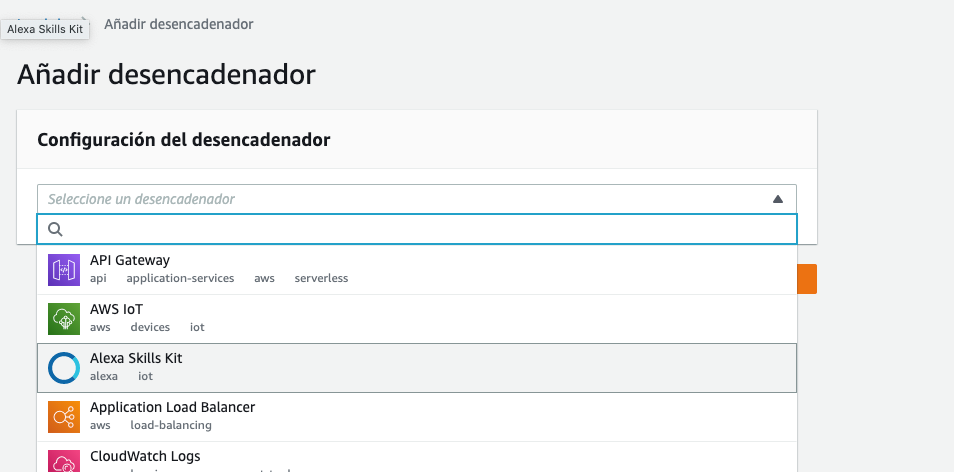
- Añadimos el trigger de Alexa en la función lambda. Y le ponemos el id de la skill.
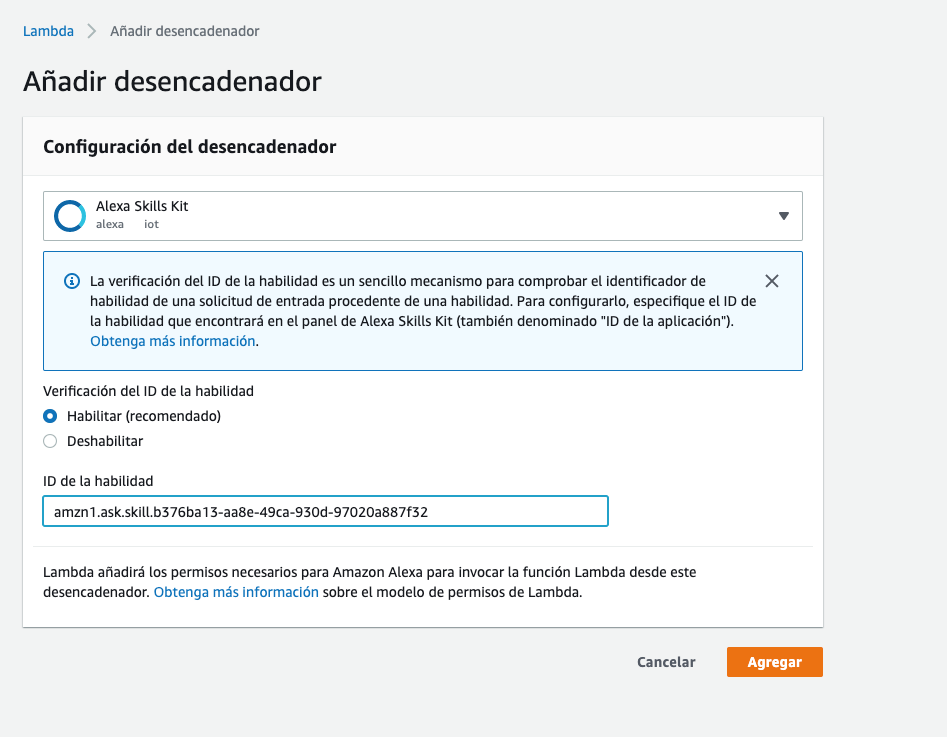
- Copiamos el ARN de la función lambda que será lo que llevemos al campo del endpoint en la Alexa Developer Console.

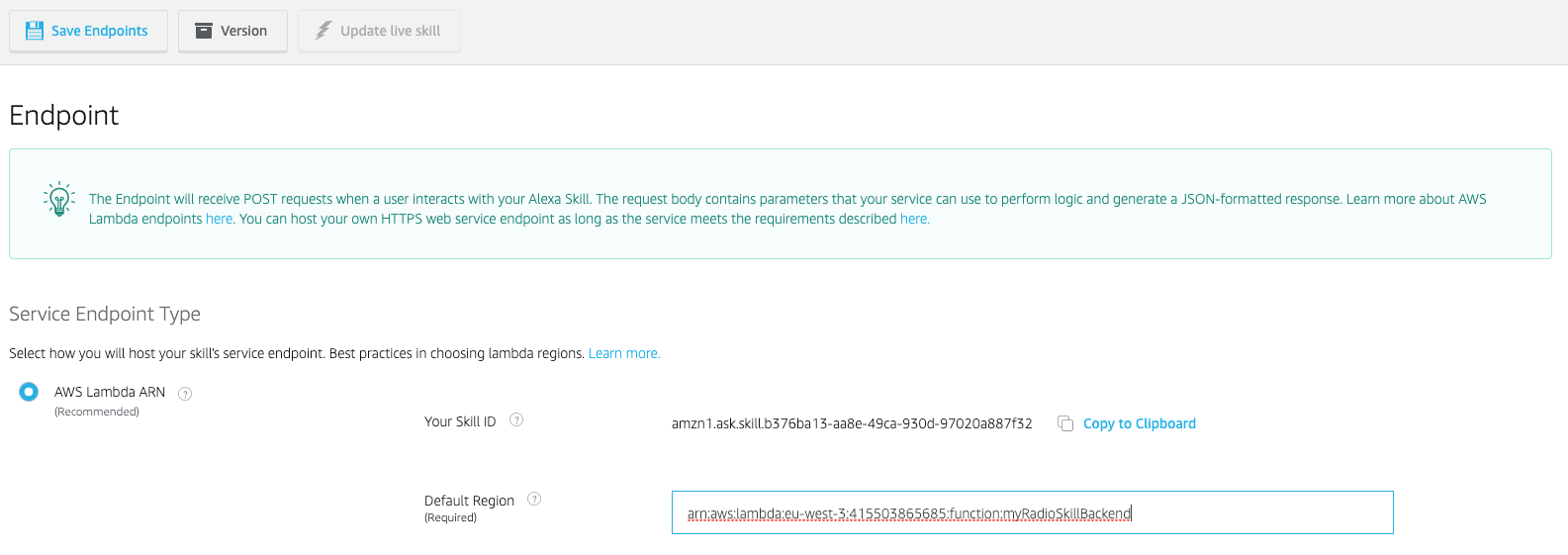
- Y al guardar el endpoint se validará esto que acabamos de configurar de tal forma que sabremos si está todo bien.
¿Y dónde se indica la URL del audio a reproducir?
Para esta skill básica de audio decidí que solo iba a manejar un audio, es decir, una URL, pero que se pudiera cambiar sin tener que tocar código. Para ello lo que tenemos que hacer es indicar la URL por una variable de entorno de la AWS Lambda.

- En la zona de variables de entorno simplemente tenemos que añadir la variable con clave
audioUrly el valor será la URL que contenga el audio.
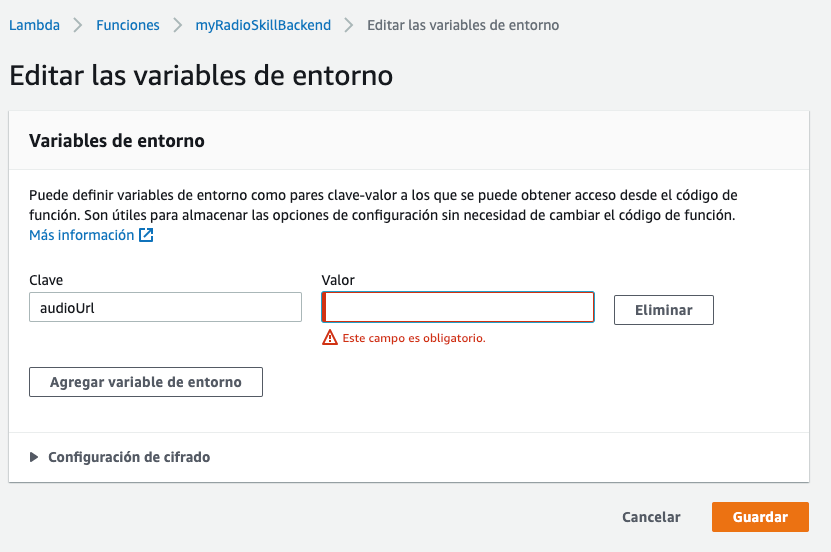
- He añadido la opción de indicar también un audio de fallback en el caso de que haya algún error. Para eso tenemos que añadir la variable de
fallbackAudioUrlde la misma forma que la anterior.

Una vez tengamos la(s) variable(s) creadas y guardada(s) ya podremos usar nuestra skill. Para probarla podemos usar el simulador de la Alexa Developer Console o un dispositivo con Alexa (ya sea un Echo o la aplicación de Amazon Alexa para el móvil). Con el simulador no vamos a poder escuchar el audio pero si inspeccionar la respuesta de la skill para ver si ha lanzando la operación de play contra la URL correcta:
Para escuchar el audio tendremos que probar la skill en un dispositivo Alexa o en la aplicación del móvil.
Y ya solo tendríamos que rellenar la info de distribución de la skill y mandarla a certificar :D
Para cualquier error no dudéis en contactarme por aquí o por twitter. Igualmente recordad que se pueden ver los logs de la AWS Lambda en la zona de "Monitorización" y ya está el código preparado para meter ahí peticiones y respuestas ;)